GPU计算架构深度解析:NVIDIA H100/B200的并行引擎与互联之道
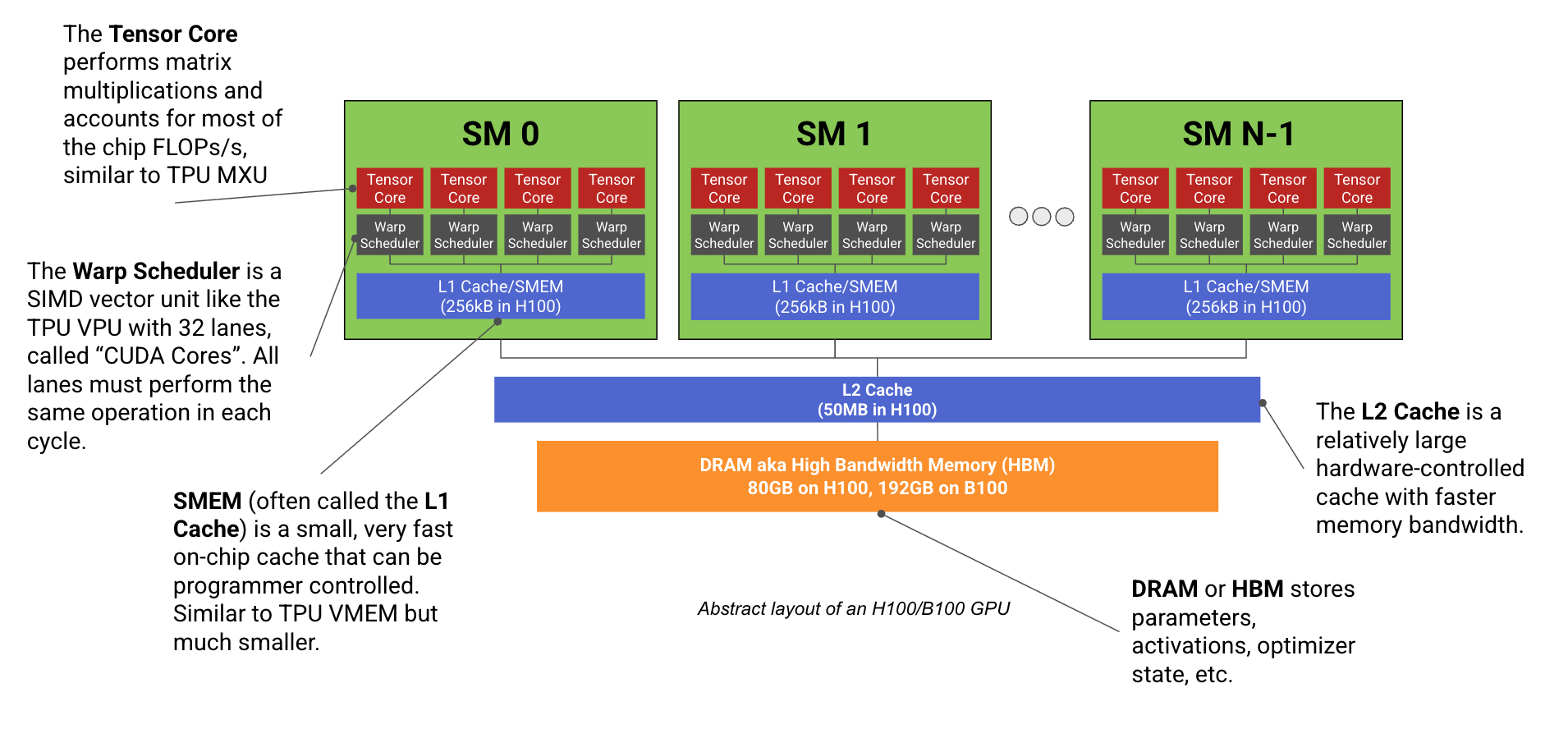
NVIDIA的GPU架构,特别是H100和B200系列,在设计上展现了对大规模并行计算的极致追求。其核心是Streaming Multiprocessor (SM) 单元,每个SM内含Tensor Core(用于矩阵乘法)、Warp Scheduler(控制CUDA核心执行向量运算)和SMEM(片上缓存)。H100拥有132个SM,B200则有148个,远超TPU的独立计算单元数量,赋予GPU在处理多任务时的灵活性。
SM的进一步细分,每个SM包含四个子分区,每个子分区拥有独立的Tensor Core、Warp Scheduler和CUDA核心。Tensor Core是计算力的主要来源,尤其是在低精度计算时,其吞吐量远超CUDA核心。CUDA核心采用SIMT(Single Instruction, Multiple Threads)模型,提供比TPU的SIMD(Single Instruction, Multiple Data)模型更灵活的线程级编程,但可能因分支发散(warp divergence)而影响性能。
内存层级上,GPU拥有HBM(主显存)、L2缓存、SMEM(L1缓存)以及寄存器文件。Blackwell架构(B200)引入了TMEM,以支持更大的Tensor Core输入。在网络互联方面,GPU采用NVLink和NVSwitch构建节点内全互联,并经由InfiniBand/Ethernet连接至更广泛的网络。H100节点内提供450GB/s的GPU间带宽,节点间通过InfiniBand提供400GB/s的带宽。GB200 NVL72则将节点内GPU数量大幅提升至72个,并将节点内带宽提升至900GB/s,节点间带宽维持400GB/s,但大幅增加了节点总出口带宽。
在模型并行策略上,数据并行(DP)和ZeRO分片在反向传播时需要AllReduce或ReduceScatter+AllGather,要求每GPU批次大小约2500个token才能达到计算瓶颈。张量并行(TP)则在激活值上需要AllGather和ReduceScatter,通常限制在单节点内或最多双节点。混合专家模型(MoE)因其稀疏性,对数据并行提出了更高要求,但通过专家并行(EP)可在一定程度上缓解。流水线并行(PP)因其低通信成本和零气泡调度,成为一种有吸引力的选择,但代码复杂性高且与ZeRO-3等分片策略存在兼容性问题。
网友讨论