Daft框架:AI文本嵌入效率革命,实现近乎100%GPU利用率
Daft框架通过优化文本嵌入流程,实现了处理海量文档的效率飞跃。该流程整合了spaCy进行句子切分,并利用Qwen3-Embedding-0.6B模型生成向量表示,最终高效写入Turbopuffer向量数据库。
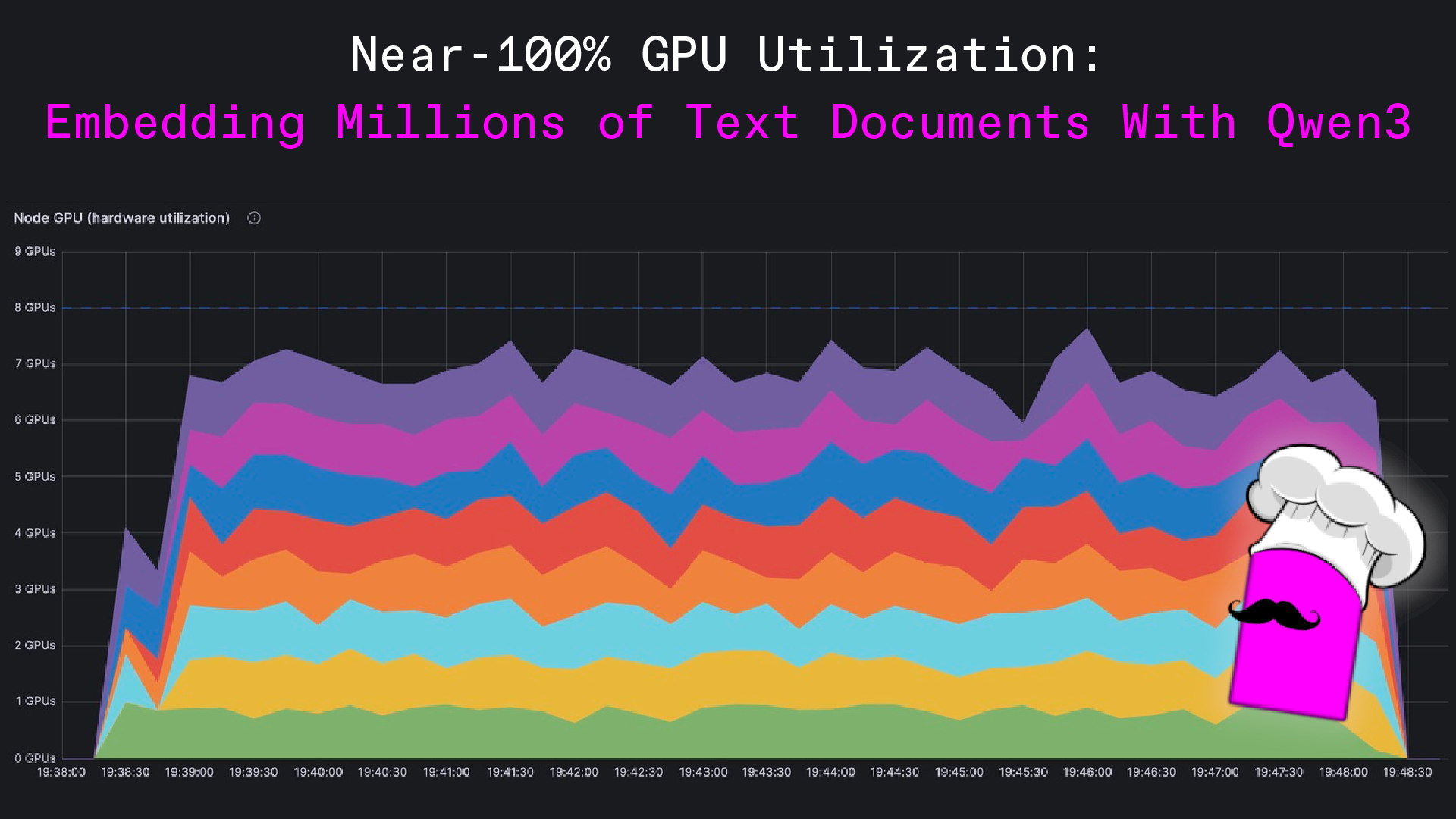
核心洞察在于,通过精细化的分布式计算策略和模型调用优化,Daft框架能够最大化GPU利用率,达到接近100%的水平。具体实现包括:利用spaCy进行高效、准确的句子级文本切分,并将其转化为结构化数据;采用SentenceTransformer库加载Qwen3-Embedding-0.6B模型,并利用bfloat16精度减少GPU内存占用,同时通过批量处理提升GPU吞吐量;通过Ray集群进行分布式计算,确保网络I/O、CPU和GPU任务并行执行。
此次技术突破预示着大规模文本数据处理在效率和成本效益方面将迎来显著提升。它不仅为AI应用中的向量检索奠定了坚实基础,更展示了通过框架级优化实现算力潜能最大化的新范式。该方法论为后续更复杂的AI模型部署和优化提供了宝贵经验,预示着AI基础设施的性能边界将被持续拓展。
Embedding Millions of Text Documents With Qwen3
Learn how to achieve near-100% GPU utilization processing millions of text documents with Qwen3 embeddings.
网友讨论