AI模型实测:开源力量崛起,速度与成本重塑效能格局
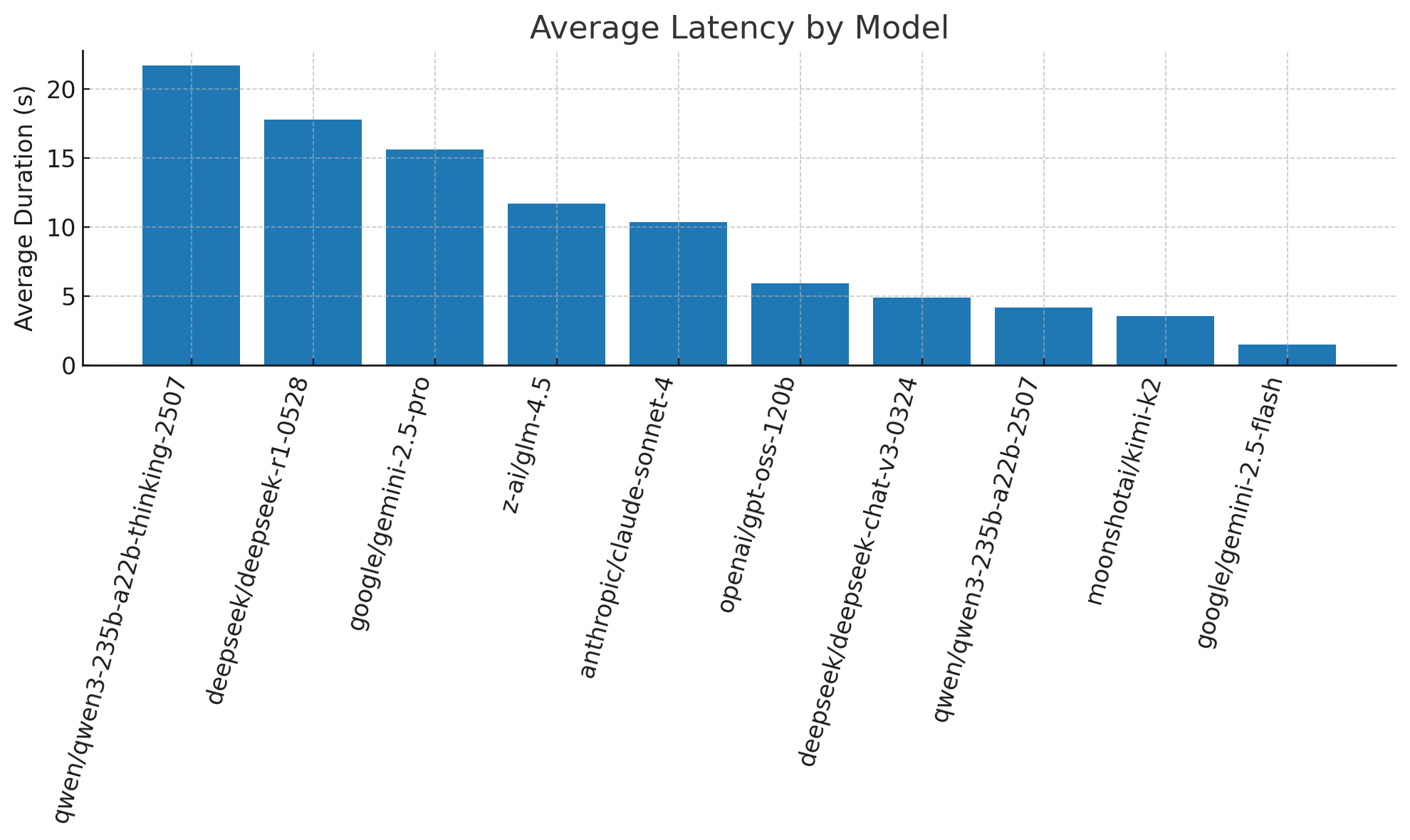
通过对130个真实用户提示的广泛评估,揭示了当前AI模型在处理编程、系统管理、技术解释及通用知识等任务上的能力边界。评估发现,几乎所有模型在绝大多数任务中均表现出较高准确性,且模型间存在显著的趋同性,尤其在通用知识类问题上。然而,在成本和响应速度(延迟与吞吐量)方面,各模型差异巨大,这成为区分模型优劣的关键。开源模型在综合表现上,尤其在代码生成和技术解释方面,往往能提供不输于甚至优于闭源模型(如Google Gemini和Anthropic Claude)的解决方案,且成本效益显著。值得注意的是,‘推理’能力并非总能带来提升,在多数简单任务中,速度和成本是更重要的考量因素,仅在特定创意任务(如诗歌创作)中,‘思考’能力模型展现出明显优势。
本次评估的结果明确指出,不存在单一的‘最佳’模型。用户应根据具体需求,灵活组合使用多个模型以达到最优效果。例如,对于日常高频查询,可优先选用DeepSeek或Qwen等模型以兼顾速度、成本与准确性。当需要更深度的分析或创意输出时,可引入具备‘思考’能力的模型作为补充。闭源模型在API访问的便捷性(如OpenAI的KYC流程)及成本上存在明显劣势,使其在实际应用中的吸引力大打折扣。作者通过定制化CLI工具和tmux脚本,实现了对多个模型的并行调用和智能切换,有效提升了AI助手的使用效率和成本效益。
Evaluating LLMs for my personal use case
My life is not a math Olympiad
网友讨论